Model conditions + diagnostics
Feb 25, 2025
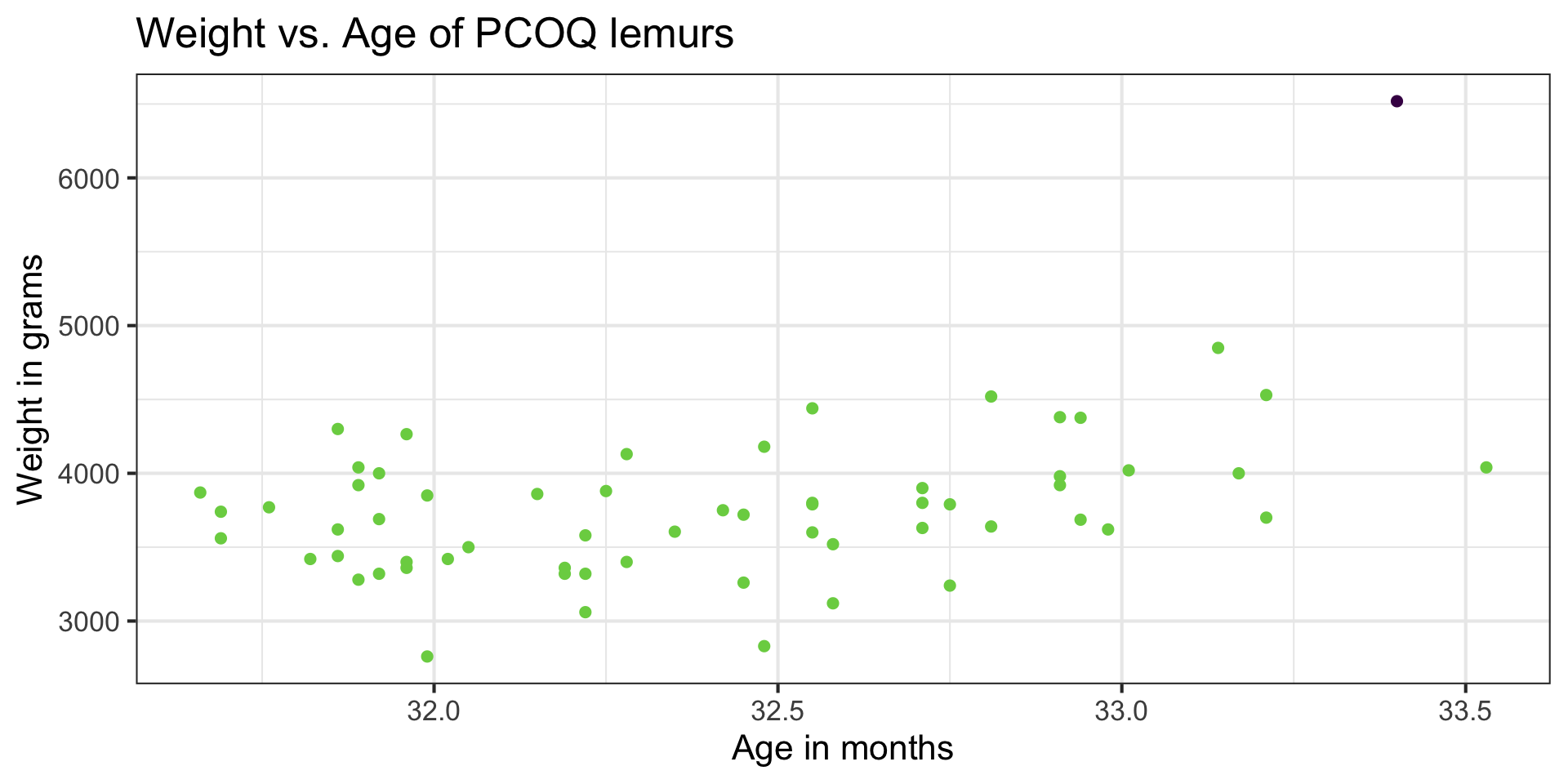
EDA
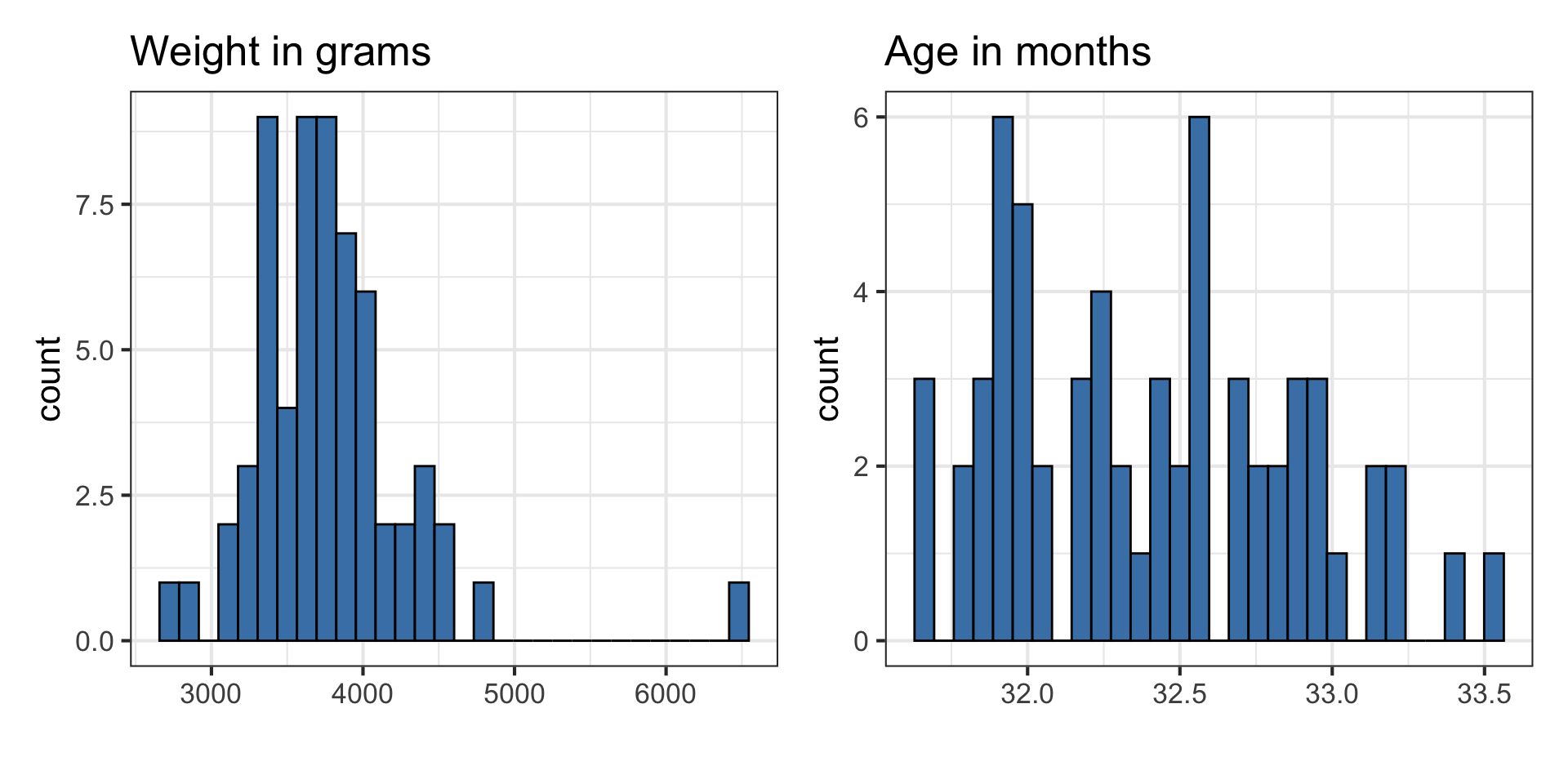
EDA
Linearity
- Look at plot of residuals versus fitted (predicted) values.
- Linearity is satisfied if there is no discernible pattern in the plot (i.e., points randomly scattered around \(residuals = 0\)
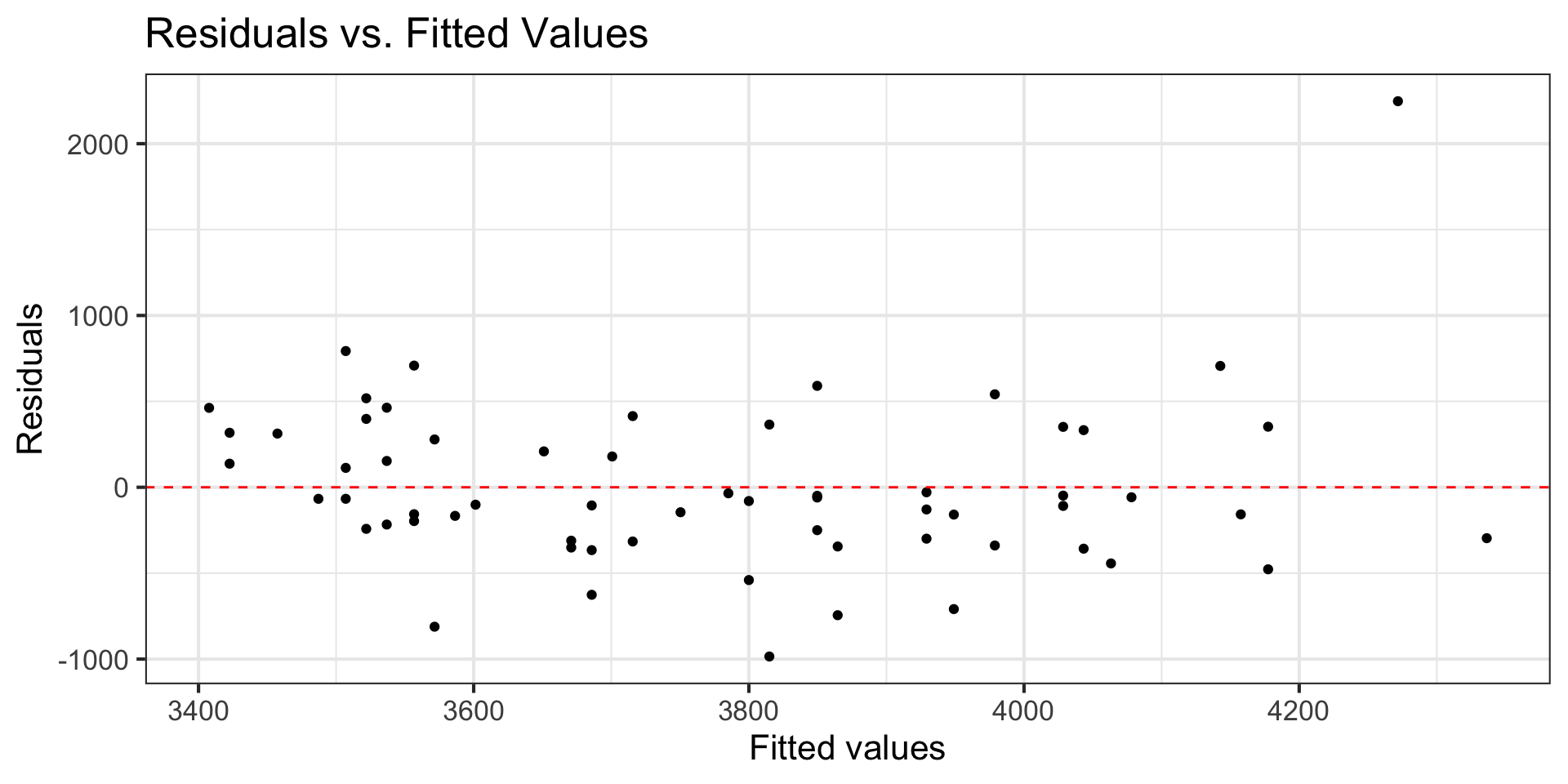
Example: Linearity not satisfied
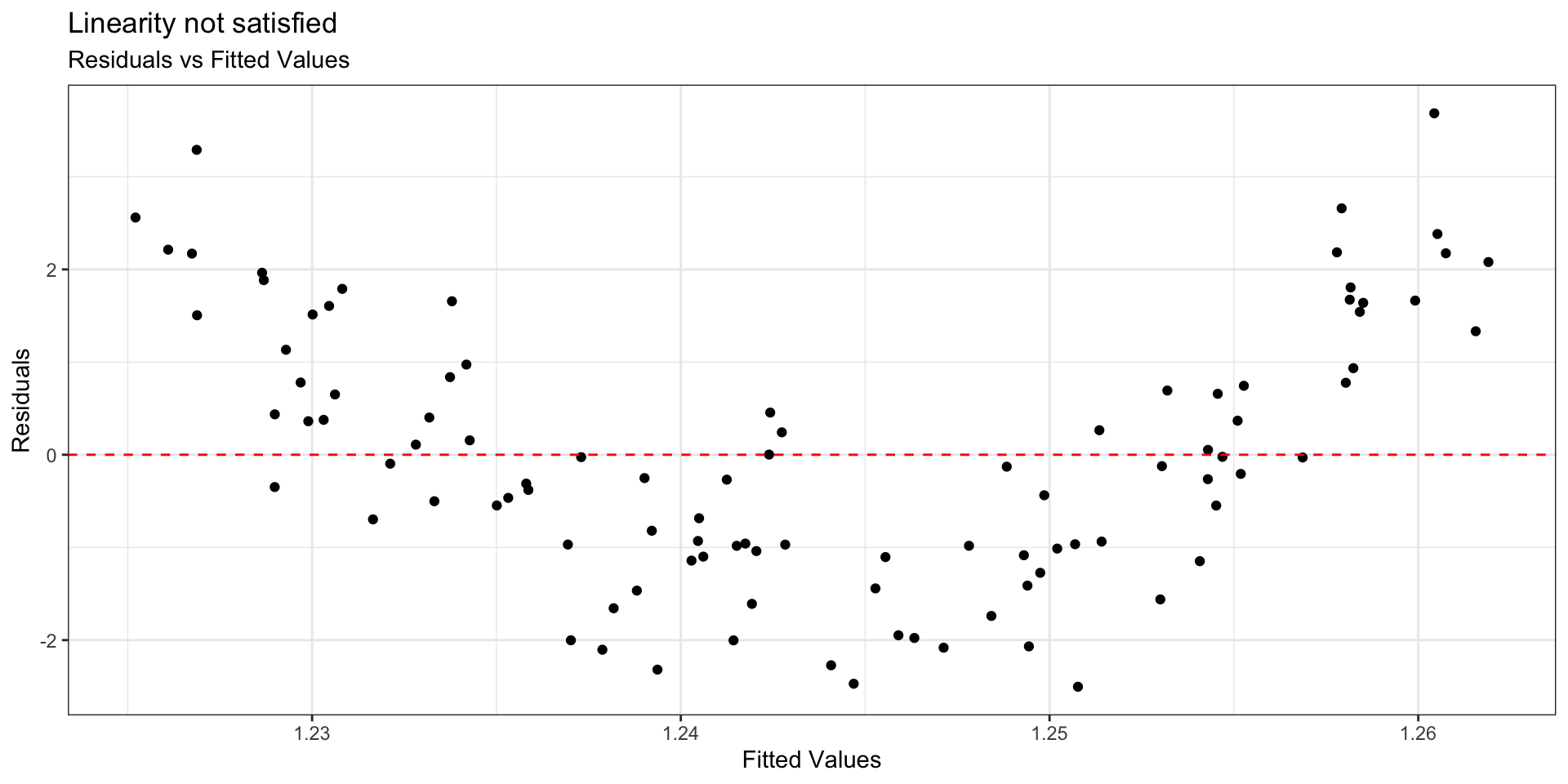
- If linearity is not satisfied, examine the plots of residuals versus each predictor.
- Add higher order term(s), as needed.
Constant variance
- Look at plot of residuals versus fitted (predicted) values.
- Constant variance is satisfied if the vertical spread of the points is approximately equal for all fitted values
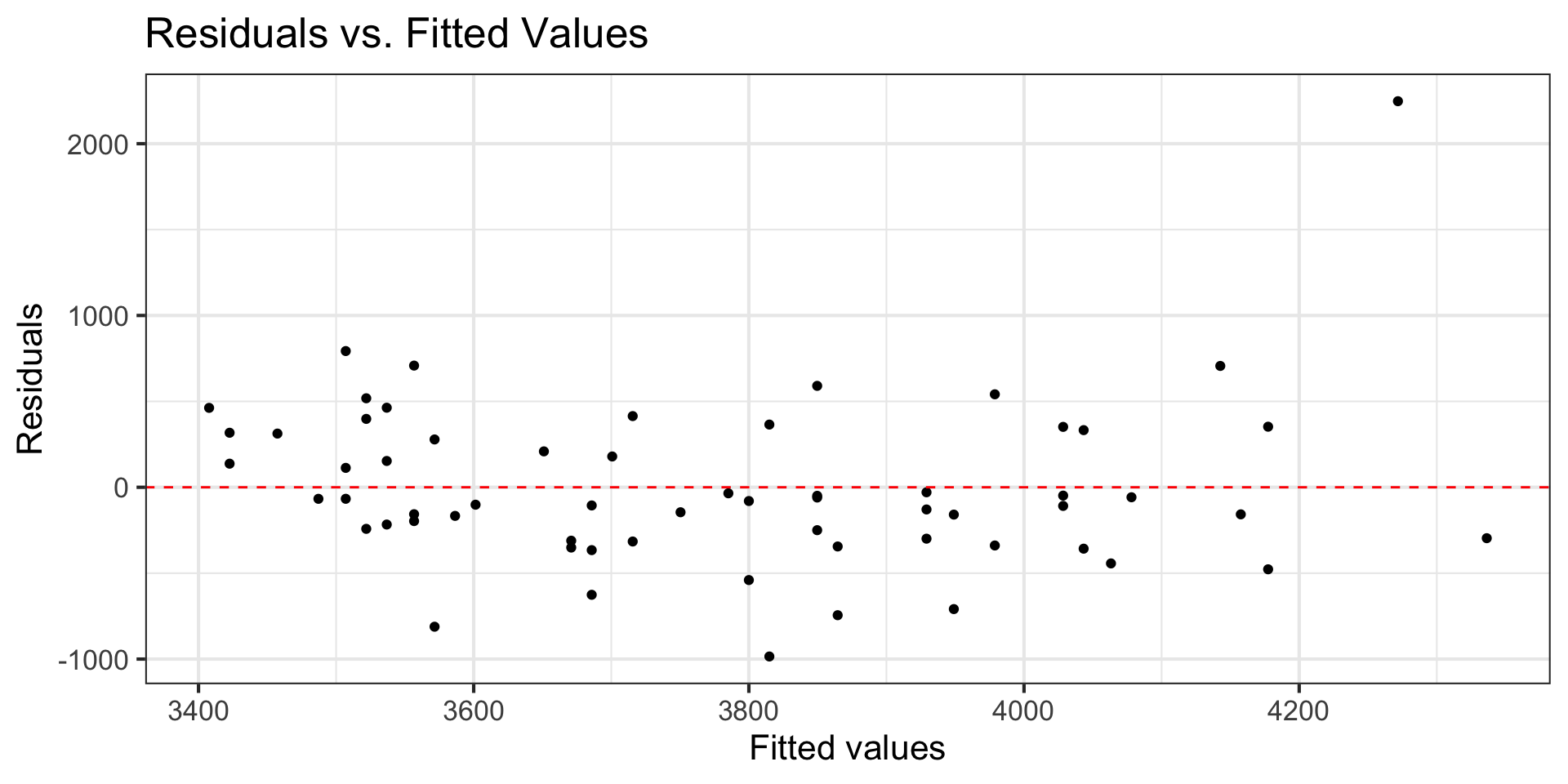
Example: Constant variance not satisfied
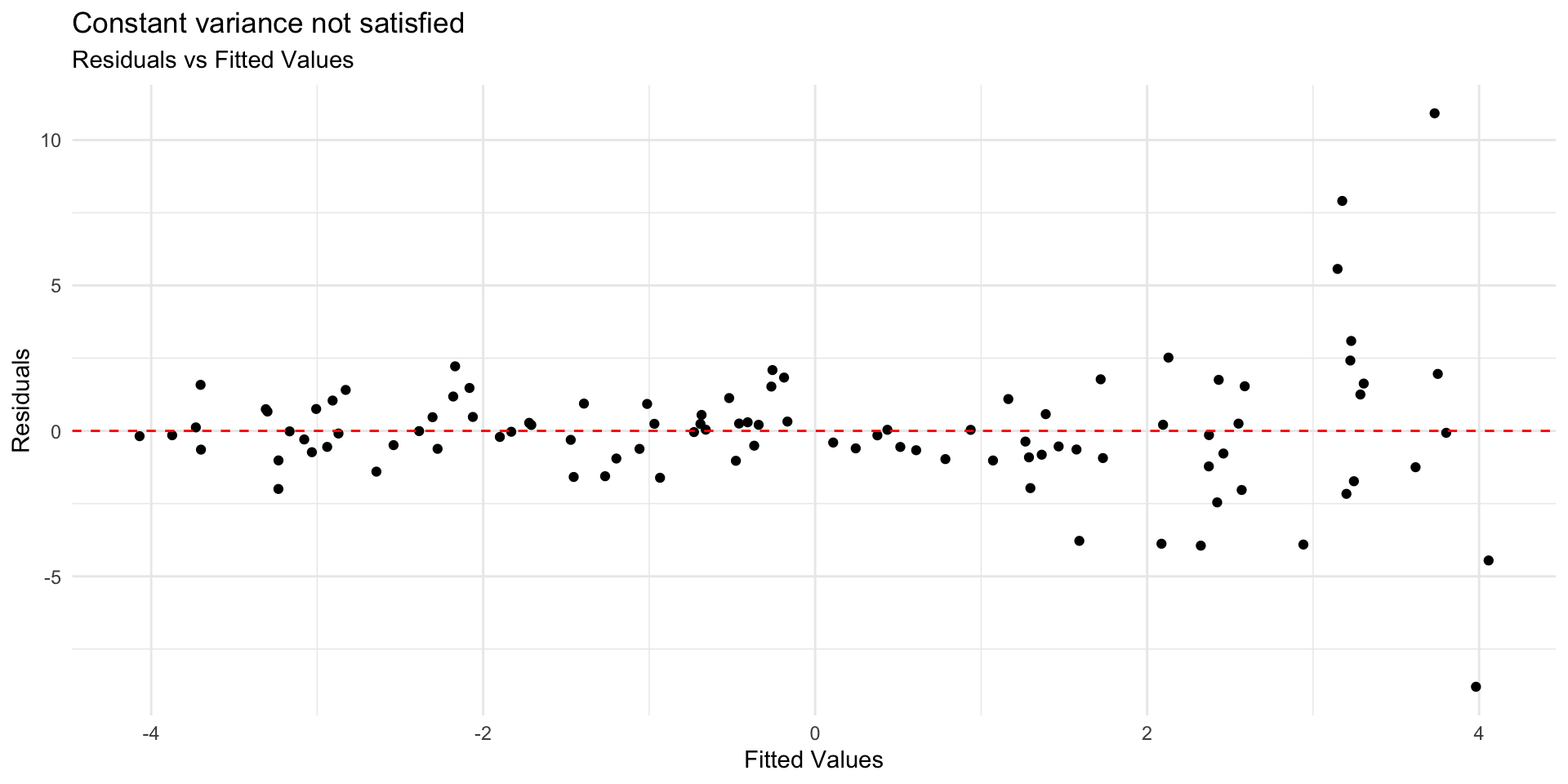
Constant variance is critical for reliable inference
Address violations by applying transformation on the response
Normality
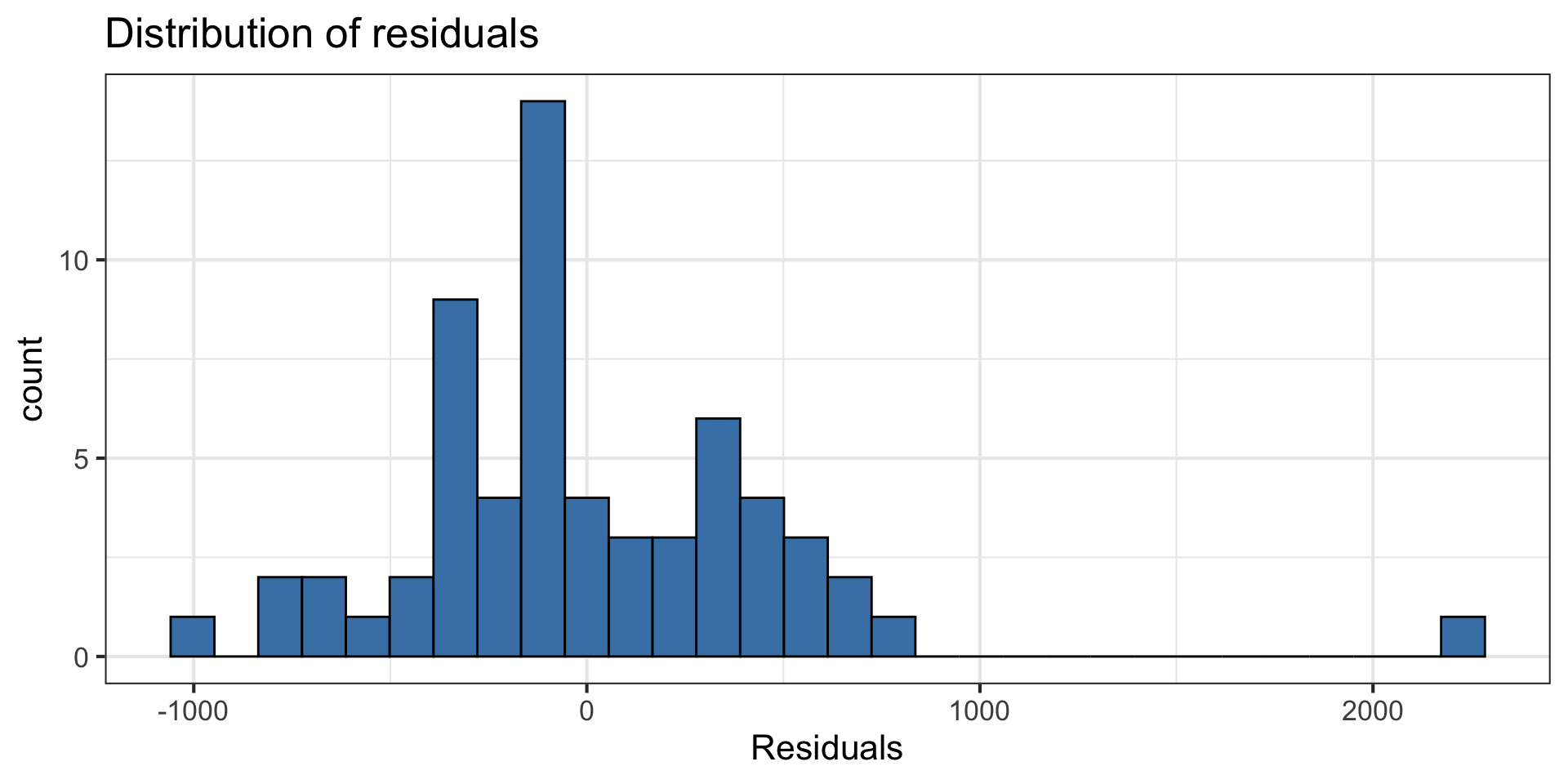
- Look at the distribution of the residuals
- Normality is satisfied if the distribution is approximately unimodal and symmetric. Inference robust to violations if \(n > 30\)
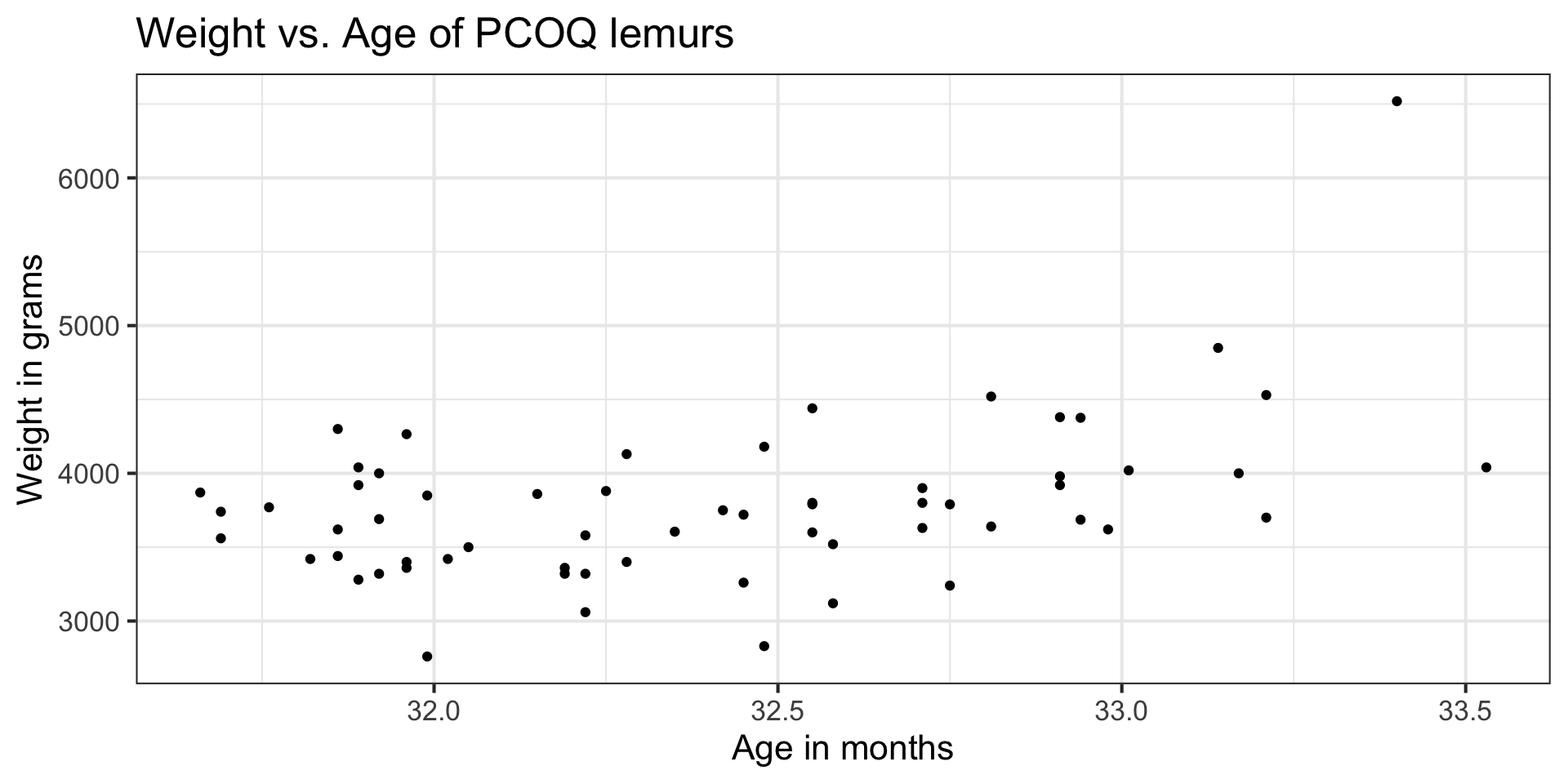
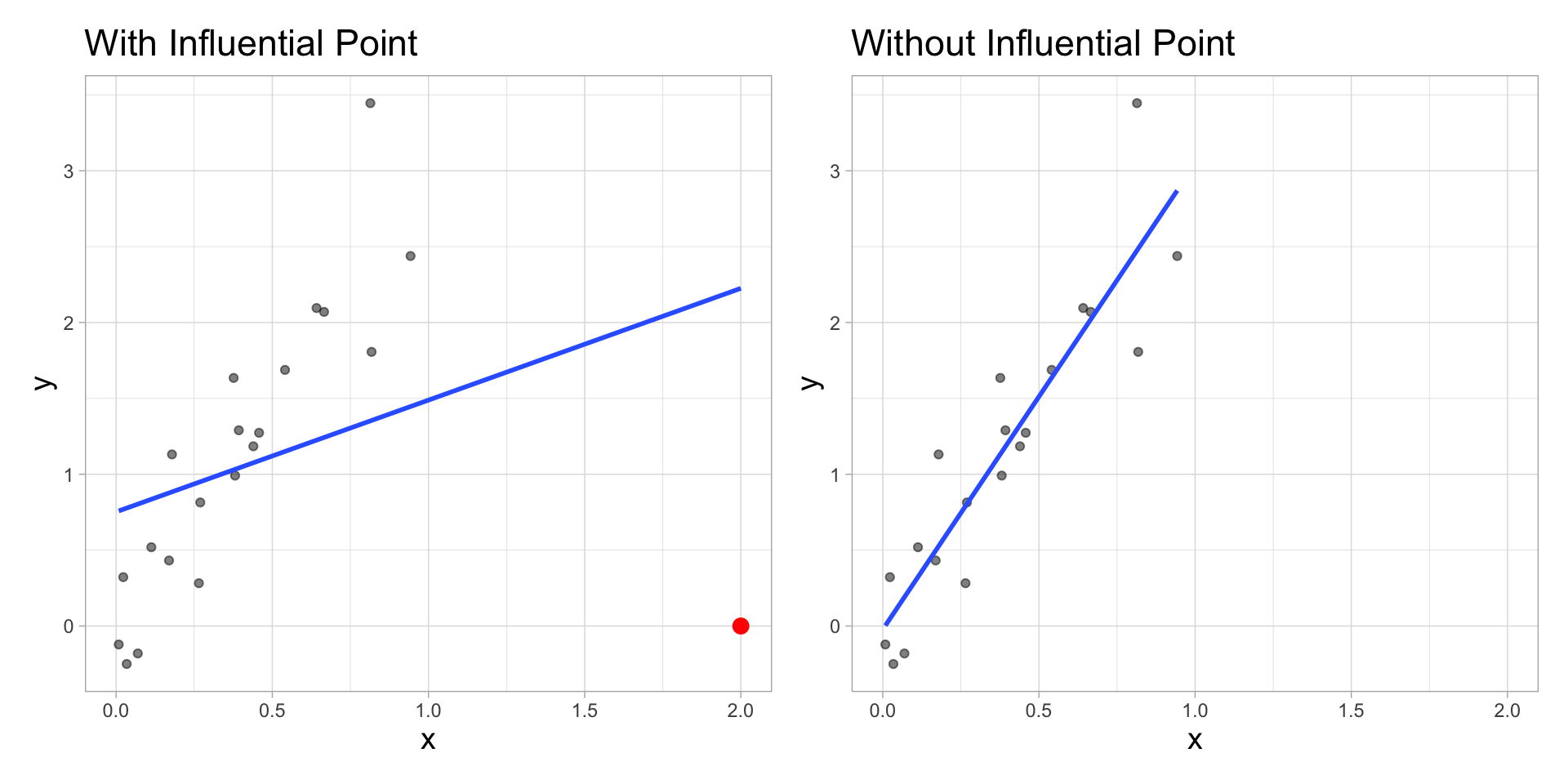
Influential Point
An observation is influential if removing has a noticeable impact on the regression coefficients
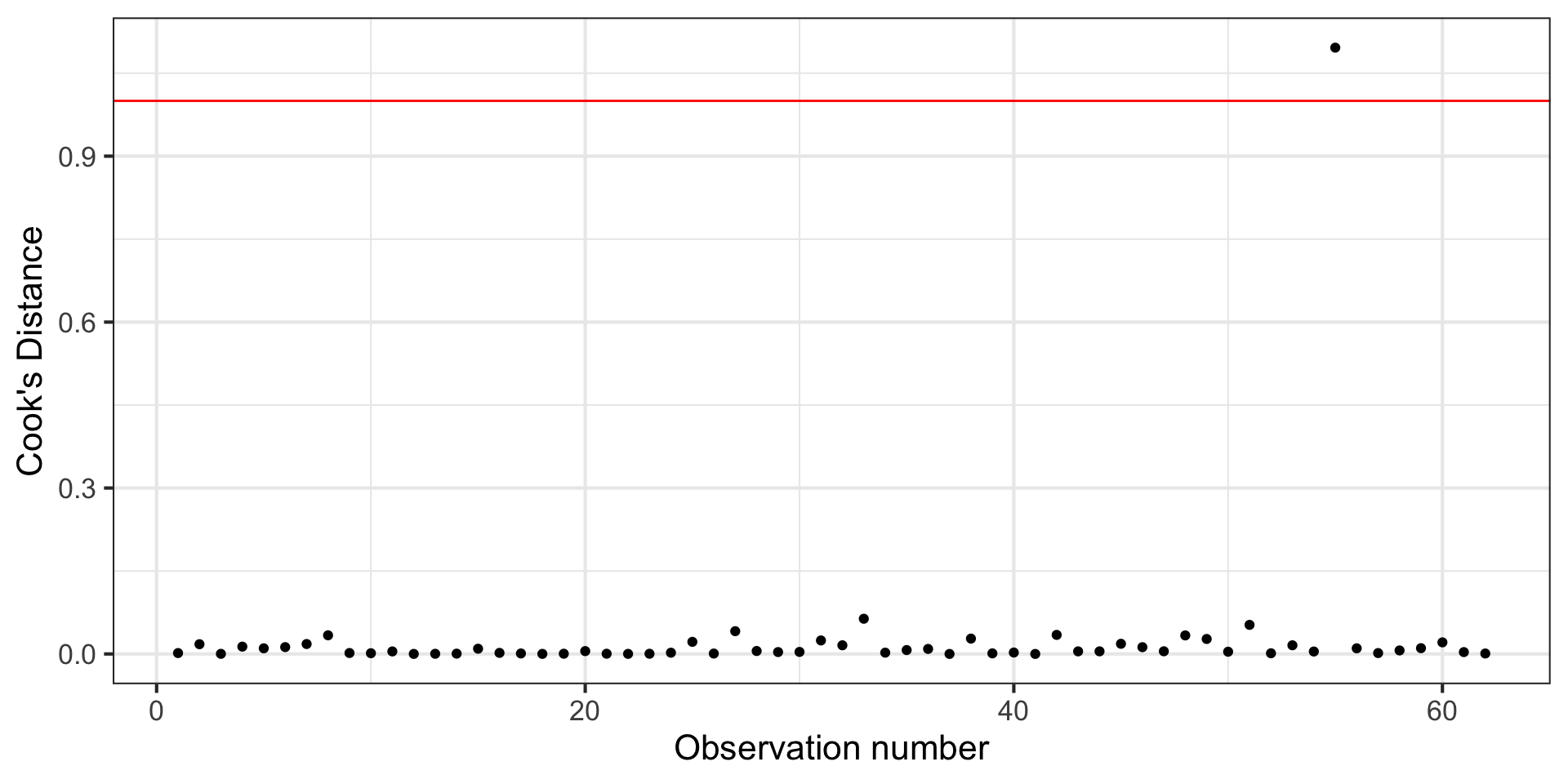
Cook’s Distance
Cook’s Distance is in the column .cooksd in the output from the augment() function
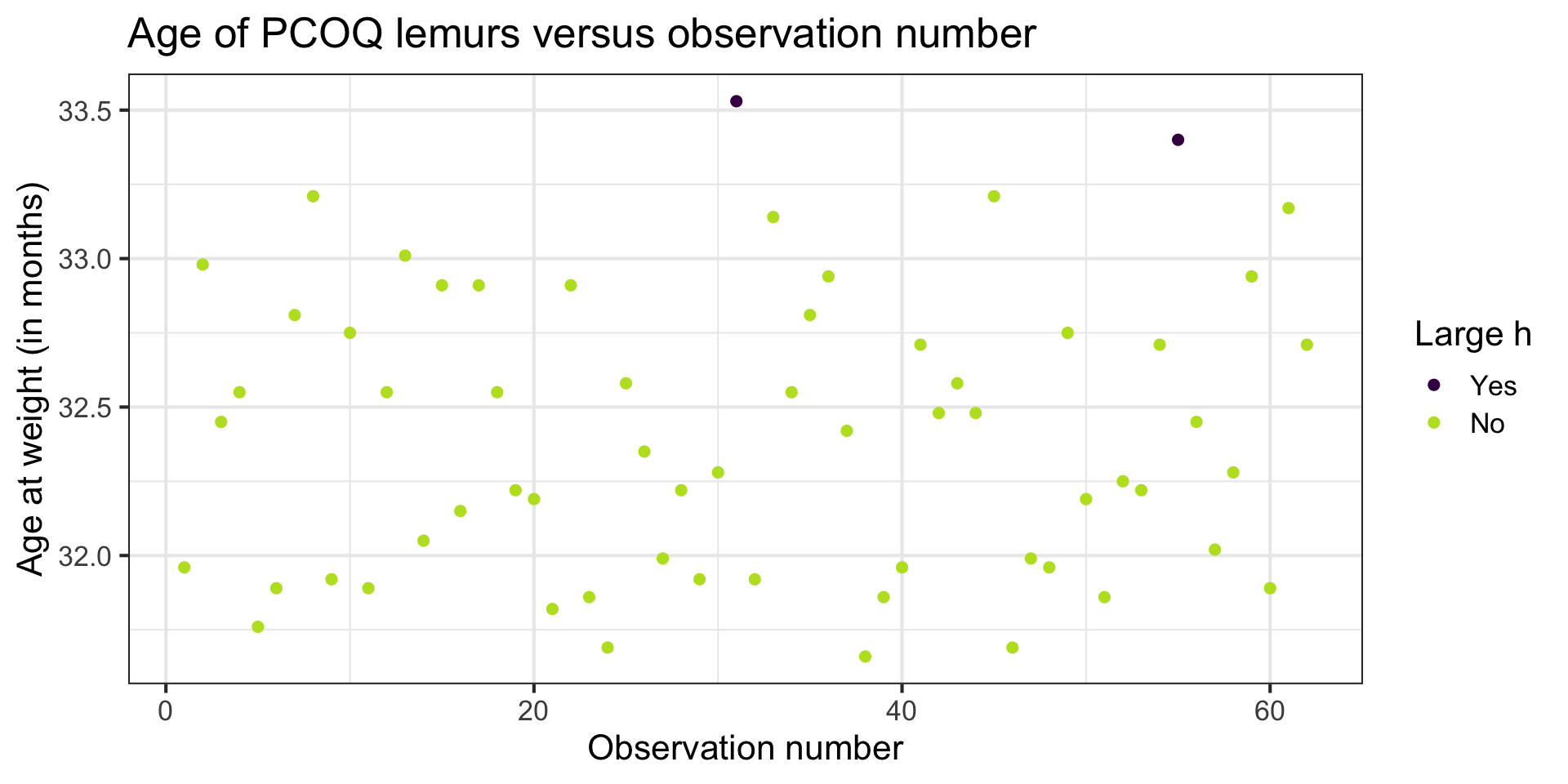
Let’s look at the data
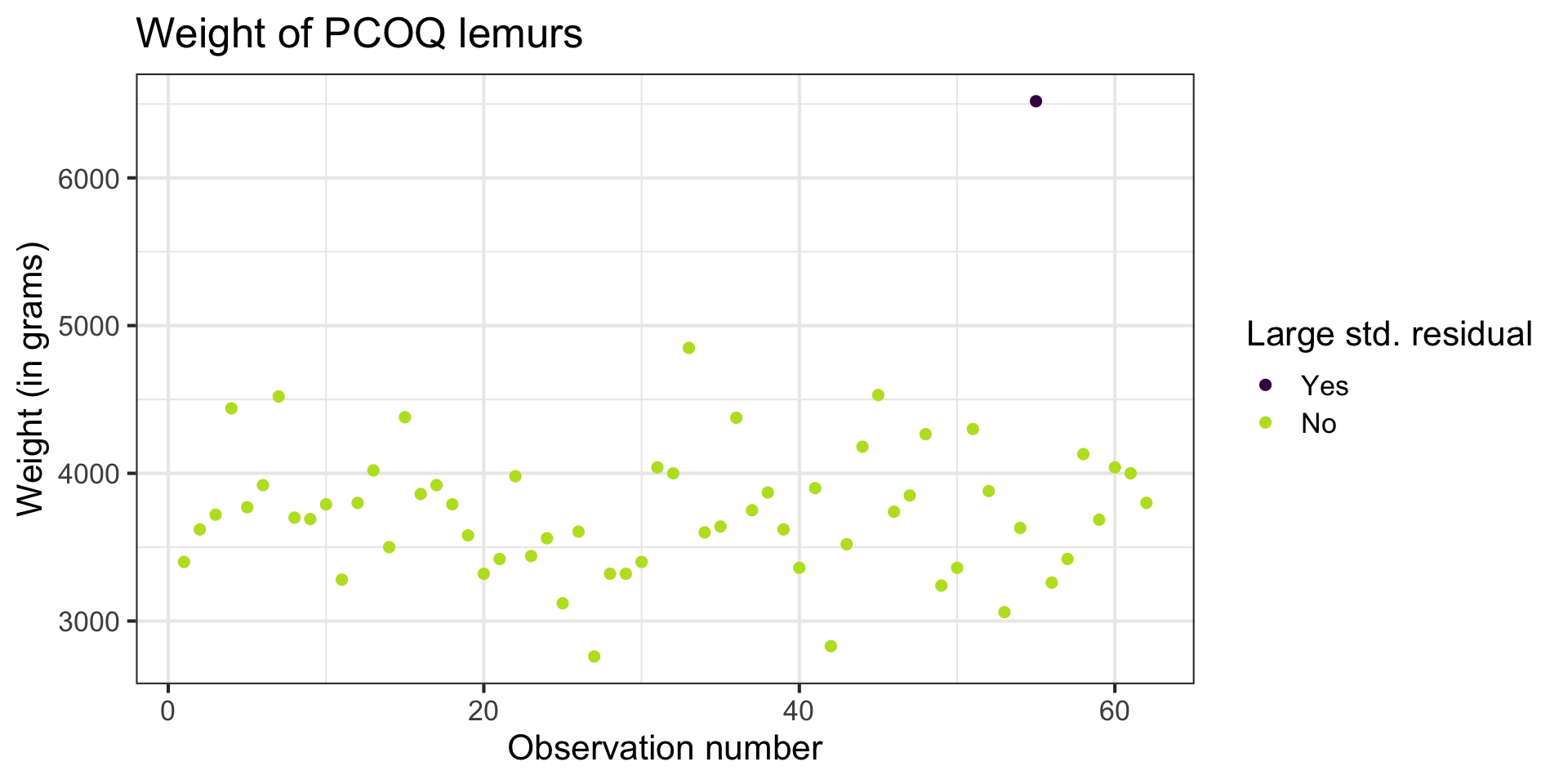
Using standardized residuals
We can examine the standardized residuals directly from the output from the augment() function
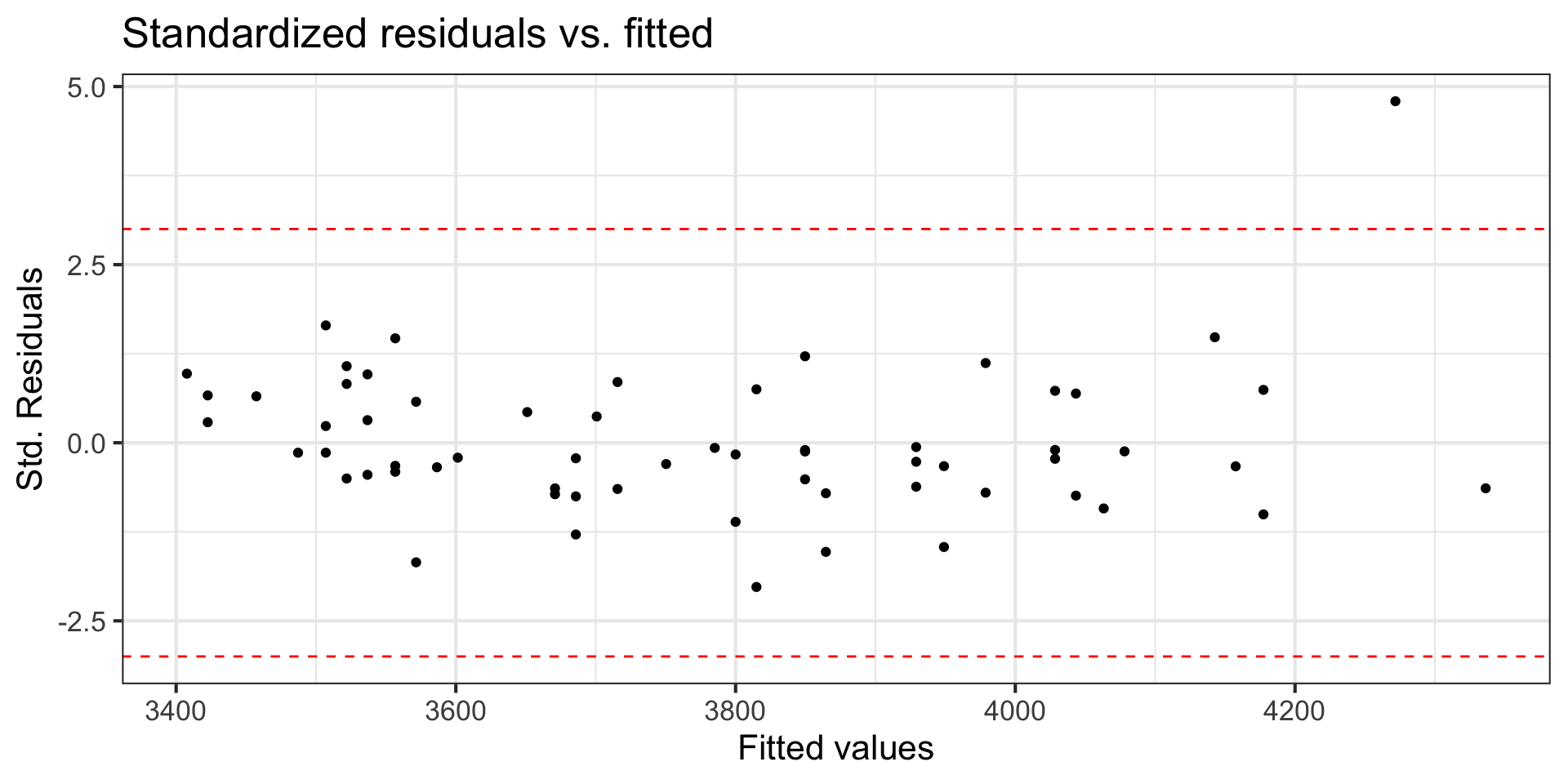
- An observation is a potential outlier if its standardized residual is beyond \(\pm 3\)
Digging in to the data
Let’s look at the value of the response variable to better understand potential outliers
Back to the influential point